
목차
ORM(Object-Relational Mapping) 라이브러리를 사용한 코드를 작성하면서 발생할 수 있는 N+1 문제를 이해하고, N+1 문제 발생 시 조치 방법에 대해 알아보자.
ORM이란?
엔티티 객체와 관계형 데이터베이스를 맵핑하여 애플리케이션이 SQL을 스스로 생성하여 실행할 수 있도록 돕는 기술 및 라이브러리를 말한다. Java를 예로 들면 JPA 표준을 따라 개발된 Hibernate라는 라이브러리가 있다. 객체 지향 언어에서 사용되며, ORM을 사용하면 개발자는 SQL을 직접 작성하지 않아도 된다는 장점이 있다. 하지만 작성한 코드에 의해 어떤 SQL이 실행되는지 이해하고 있어야 문제가 발생했을 때 쉽게 해결할 수 있다.
지연 로딩과 즉시 로딩
엔티티를 조회할 때 연관 관계에 있는 엔티티의 데이터까지 한 번의 쿼리로 가져오는 것을 즉시 로딩이라고 하고, 연관 관계에 있는 엔티티를 처음부터 가져오지 않고 필요할 때 추가적으로 쿼리를 날려서 가져오는 것을 지연 로딩이라고 한다. 지연 로딩이 필요한 이유는 비즈니스 로직에서 굳이 연관 관계에 있는 엔티티의 데이터가 필요 없는 경우가 많기 때문이다. 그런 경우엔 연관 관계에 있는 엔티티의 데이터를 추가로 조회해 오는 비용을 감수할 필요가 없다. 그래서 기본적으로 지연 로딩으로 데이터를 가져오되, 연관 관계에 있는 엔티티가 필요한 상황에서는 처음부터 즉시 로딩 하는 방식으로 구현하는 편이다.
지연로딩+연관 관계의 엔티티 조회 = N+1 문제
조회된 N개의 엔티티가 연관 관계에 있는 엔티티의 데이터를 조회할 때, 연관 관계에 있는 엔티티를 지연 로딩으로 가져오게 설정 되어 있을 경우 애플리케이션은 최대 N 번의 쿼리를 추가적으로 더 실행하게 된다. 이것이 그 유명한 N+1 문제다. ORM에 익숙하지 않을 때 실수하기 쉬운 부분이다. ORM에 의해 생성되는 SQL을 DEBUG 로그로 남기고 테스트 과정에서 로그를 확인하자. 예상하지 못한 많은 수의 쿼리가 로그에 출력 되고 있다면 N+1 문제가 발생하고 있는 것은 아닌지 의심해 보아야 한다.
Hibernate N+1 문제 예시
JPA 구현체인 Hibernate를 사용한 예시를 살펴보자. 엔티티의 관계를 설명할 때 흔히 사용되는 Member(멤버, 자식 엔티티)와 Team(팀, 부모 엔티티)의 N:1 관계를 가정한다.
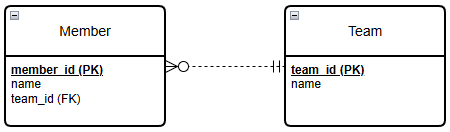
위 ERD에 따라서 Team, Member 엔티티를 정의한다. 엔티티의 PK는 자동으로 생성하고, Member 엔티티의 team 필드에는 지연 로딩을 적용한다.
// Team.java
@Entity
@Table(name = "team")
public class Team {
@Id
@Colum(name = "team_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
}
// Member.java
@Entity
@Table(name = "member")
public class Member {
@Id
@Colum(name = "member_id")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "team_id")
private Team team;
}테스트를 위해 1개의 Team 데이터, 10000개의 Member 데이터를 추가한다.
-- 1개의 Team 데이터 추가
INSERT INTO team(name) VALUES('그린뉴런 팀');
-- 10000개의 Member 데이터 추가
INSERT INTO member(name, team_id) VALUES('홍길동', 1);
INSERT INTO member(name, team_id) VALUES('이순신', 1);
...
INSERT INTO member(name, team_id) VALUES('세종대왕', 1);이 상황에서 모든 멤버의 팀 이름을 출력하는 로직을 실행한다.
List<Member> members = memberRepository.findAll(); // (1) 쿼리 1번 실행 (N 개의 Member 조회)
for (Member member : members) {
// (2) 여기서 각 Member의 Team을 가져올 때마다 추가 쿼리 발생 (N번)
for (Team team : member.getTeam()) {
System.out.println("멤버 이름: " + member.getName() + ", 팀 이름: " + team.getName());
}
}만약 멤버가 10000개라면, 아래와 같이 쿼리는 총 1(Member 전체) + 10000(각 Member의 Team 조회) = 1 + 10000 번 실행된다.
SELECT * FROM member; // 전체 Member 조회
SELECT t.* FROM member m JOIN team t ON m.team_id = t.team_id WHERE member_id = 1; // Member 1의 Team 조회
SELECT t.* FROM member m JOIN team t ON m.team_id = t.team_id WHERE member_id = 2; // Member 2의 Team 조회
...
SELECT t.* FROM member m JOIN team t ON m.team_id = t.team_id WHERE member_id = 3; // Member 10000의 Team 조회N+1 문제 조치 방법
N:1 관계에서 N+1 문제를 해결하려면 한 번의 쿼리로 필요한 데이터를 모두 가져와야 한다.

(Gemini가 생성한 이미지)
Fetch Join
부모 엔티티를 조회할 때 한 번의 쿼리에서 자식 엔티티의 데이터까지 조인해서 가져오면 된다. JPA에서는 이를 fetch join 이라고 한다.
// MemberRepository.java
@Query("select m from Member m join fetch m.team")
List<Member> findAllWithTeam();@EntityGraph
위에서 처럼 JPQL을 직접 작성하지 않고 애너테이션을 사용하여 fetch join 하는 방법도 있다. @EntityGraph를 사용할 경우 내부적으로 left outer join이 사용되므로 Team이 null이 될 수 있다면 NullPointerException을 주의해야 한다.
@EntityGraph(attributePaths = {"team"})
List<Member> findAll();참고 자료
- Vlad Mihalcea (Hibernate 개발자)의 N+1 가이드
- [Spring Data JPA] @EntityGraph – 쌈뽕코딩


