
AI에게 테스트를 맡겼더니 커버리지는 80%가 넘는데, 정작 버그는 잡지 못했던 경험이 있으신가요?
AI 코드 어시스턴트는 테스트 작성에 분명히 도움이 됩니다. 반복적인 코드도 금방 작성해주고 요청에 따라 다양한 케이스에 대해 테스트 코드를 작성해줄 수 있습니다. 하지만 “AI가 테스트를 써줬으니 됐다”는 생각으로 AI를 너무 믿는 것은 위험합니다. AI가 만든 테스트는 코드의 동작을 검증하는 게 아니라, AI 자신의 가정을 검증하는 경우가 많기 때문입니다.
이 글은 그 이유와, 실제로 도움이 되는 사용 방법을 3가지 원칙으로 정리합니다.
AI는 테스트를 어떻게 만드는가?
AI 코드 어시스턴트에게 테스트 코드를 요청하면, 도구가 하는 일은 이렇습니다. 주어진 코드를 읽고, 그 코드가 하는 동작을 파악한 뒤, 그 동작을 검증하는 테스트를 작성합니다. 문제는 거기에 있습니다.
public class TaxCalculator {
public double calculateTax(double amount, String country) {
return amount * 0.1; // 일단 10%로 구현
}
}이 코드를 보여주고 “테스트 써줘”라고 하면, AI는 10% 계산이 맞는지 확인하는 테스트를 만듭니다. 여기서 “발생할 수 있는 예외 케이스도 포함해줘”라고 추가하면, AI는 null 입력, 음수, 빈 문자열 같은 일반적인 케이스를 꽤 잘 잡아냅니다.
하지만 한국 사용자에게는 10%가 적용 되어야 하고 캐나다 사용자에게는 5%가 적용돼야 한다는 사실, 특정 국가 코드는 서비스 미지원이라 예외를 던져야 한다는 정책과 같은 비즈니스 룰은 코드에 없으면 AI도 알 방법이 없습니다.
즉, AI가 잘 잡는 것과 모르는 것은 명확히 나뉩니다.
- AI가 잘 잡는 것: 타입 수준의 예외(null, 음수, 빈 값 등 코드에서 읽어낼 수 있는 입력값 검증)
- AI가 모르는 것: 비즈니스 룰에서 나오는 케이스(국가별 세율, 서비스 정책, 도메인 제약 등)
실제로 이 문제는 현장에서도 반복적으로 보고되고 있습니다. QA 실무자들이 공통적으로 지적하는 패턴이 있는데, AI가 오류 없이 실행되지만 아무 의미 있는 것도 검증하지 않는 테스트를 생성하는 경우입니다. 테스트는 통과하지만, 버그는 그대로 배포됩니다(AI Testing Adoption Gap: Hype vs Reality in QA, 2025). 또한 AI 테스트 자동화 생성을 다룬 연구(MDPI, 2025)에 따르면 AI가 생성한 테스트는 해피 케이스(정상 동작하는 케이스)에 과도하게 집중하는 경향이 있는데, 아이러니하게도 해피 케이스는 이미 잘 동작하고 있을 가능성이 높아 테스트 가치가 가장 낮은 영역입니다.
“어떤 비즈니스 케이스가 존재해야 하는가”라는 판단은 도메인을 아는 사람만 할 수 있습니다. 그걸 안다면, 처음부터 명시해서 전달하는 게 더 확실한 방법입니다.
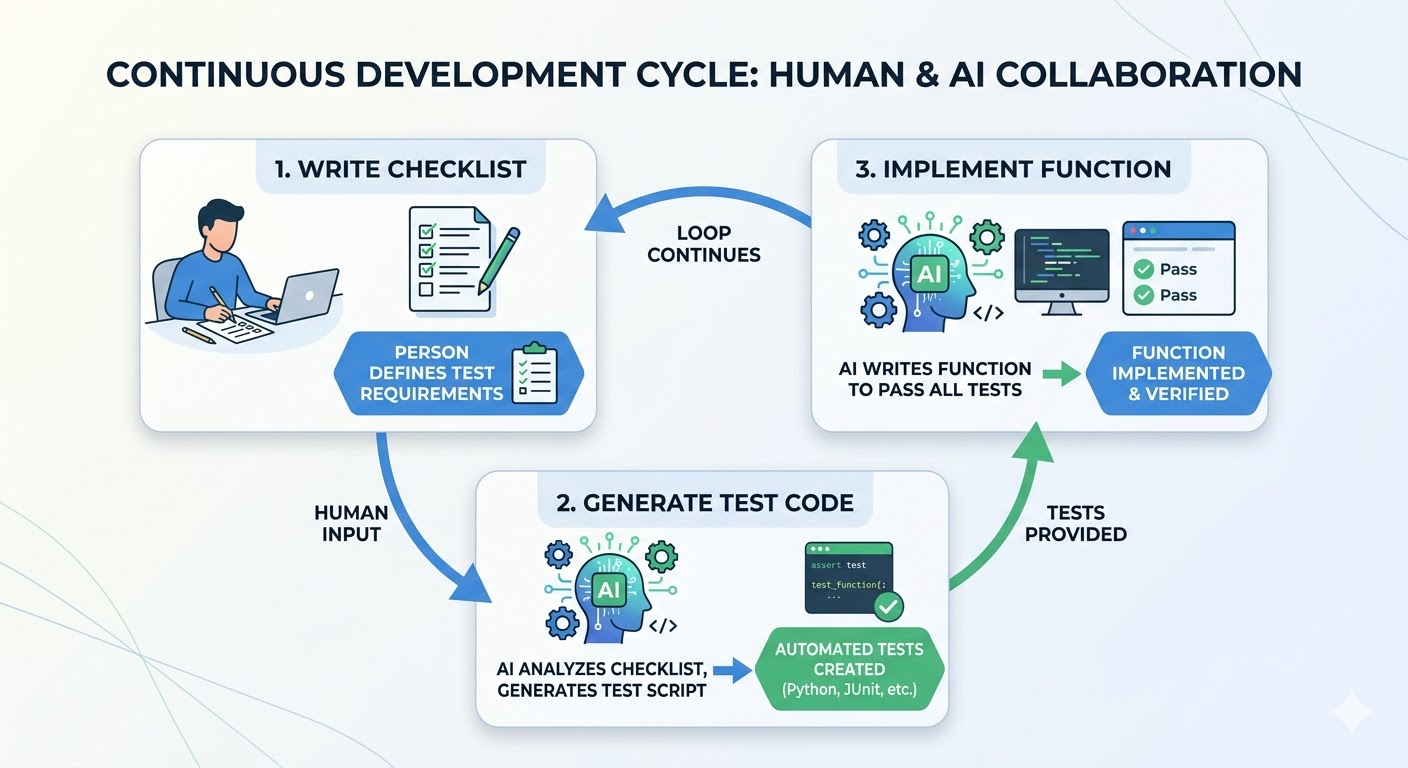
원칙 1. 테스트 케이스 목록은 내가 먼저 만든다
가장 단순하면서 효과가 큰 변화입니다. AI에게 테스트를 요청하기 전에, 테스트해야 할 케이스를 내가 먼저 나열합니다.
나쁜 프롬프트
TaxCalculator의 calculateTax 메서드 단위 테스트 작성해줘.좋은 프롬프트
TaxCalculator.calculateTax(double amount, String country) 메서드의
테스트를 JUnit 5로 작성해줘.
아래 케이스를 반드시 포함해야 해:
- country가 "KR"이면 세율 10% 적용
- country가 "CA"이면 세율 5% 적용
- amount가 음수면 IllegalArgumentException
- amount가 0이면 0.0 반환
- 지원하지 않는 country 코드면 IllegalArgumentException차이는 명확합니다. 첫 번째는 AI가 케이스를 결정합니다. 두 번째는 내가 결정하고, AI는 코드로 변환하는 역할을 합니다.
앞서 말했듯, AI는 null이나 음수 같은 일반적인 예외 케이스는 스스로 잘 떠올립니다. 하지만 비즈니스 룰에서 나오는 케이스는 내가 먼저 알고 명시해줘야 합니다. 테스트 케이스 목록을 작성할 때 “타입 수준의 검증은 AI에게, 비즈니스 룰은 내가”라는 기준으로 역할을 나누면 효율적입니다.
원칙 2. 컨텍스트를 파일로 정리해둔다
AI가 엉뚱한 테스트를 만드는 가장 흔한 이유는 컨텍스트 부족입니다. 코드베이스의 관례, 비즈니스 룰, 알려진 예외 동작을 모른 채 생성하면 일반적인 케이스만 다루는 표면적인 테스트가 나옵니다.
이를 해결하는 좋은 방법은 프로젝트 루트에 컨텍스트 파일을 만들어두는 것입니다. Claude Code라면 CLAUDE.md, Cursor라면 .cursorrules 같은 파일에 프로젝트의 테스트 관례를 미리 정리해두면, 매번 프롬프트에 설명을 붙여넣지 않아도 AI가 처음부터 프로젝트 맥락에 맞는 테스트를 생성합니다.
## Testing
- 테스트 프레임워크: JUnit 5 + Mockito
- 외부 HTTP 호출은 Mockito로 목킹
- DB 테스트는 H2 in-memory DB 사용 (실제 DB 연결 금지)팀 전체가 같은 파일을 공유하면 AI가 생성하는 테스트의 품질도 자연스럽게 일관성을 갖추게 됩니다.
원칙 3. 구현 전에 테스트 계획을 먼저 검토한다
코드를 AI에게 맡기기 전에, 테스트 계획만 먼저 뽑아보게 하고 검토하는 단계를 넣으면 가장 비용이 낮은 시점에 방향을 수정할 수 있습니다.
1단계: "이 함수를 구현하기 전에, 어떤 케이스를 테스트해야 할지
리스트만 먼저 뽑아줘."
2단계: 리스트 검토 → 빠진 비즈니스 케이스 추가, 잘못된 가정 수정
3단계: "이 테스트 케이스들을 기반으로 테스트 코드를 작성해줘."
4단계: "이 테스트를 통과하도록 함수를 구현해줘."이 순서는 TDD의 흐름과 같습니다. AI가 테스트를 먼저 쓰면, 구현 코드는 자연스럽게 그 테스트를 통과하도록 만들어집니다. 반대로 구현 후에 테스트를 요청하면, AI는 이미 작성된 구현을 변호하는 테스트를 쓰는 경향이 있습니다.
테스트를 먼저 작성하는 방식의 효과는 오래전부터 연구되어 왔습니다. Microsoft와 IBM의 팀을 대상으로 한 연구에서 TDD를 적용한 프로젝트는 그렇지 않은 프로젝트 대비 결함 밀도가 40~90% 감소한 것으로 나타났습니다. 다만 TDD는 초기 개발 속도를 15~35% 늦출 수 있다는 점도 함께 보고되었으므로, 팀 상황에 맞게 적용 범위를 조절하는 것이 현실적입니다. AI와 함께 쓸 때의 추가적인 이점도 있습니다. 테스트가 먼저 정의되어 있으면 AI가 구현을 생성할 때 명확한 성공 기준을 갖게 되어, 모호한 요구사항에서 비롯되는 환각을 줄이는 데 도움이 됩니다.
마치며
AI 어시스턴트를 테스트 작성에 활용해 보면서 느낀 건, 이 도구가 “테스트를 대신 써주는 것”이 아니라 “내가 정의한 것을 코드로 옮겨주는 것”에 가깝다는 점입니다. 비즈니스 룰을 알고, 엣지 케이스를 판단하고, 무엇을 검증할지 결정하는 일은 여전히 개발자의 몫입니다.
처음 AI로 테스트를 써볼 때는 커버리지 숫자가 올라가는 게 뿌듯하게 느껴질 수 있습니다. 하지만 그 테스트가 실제 버그를 잡아줄 수 있는지가 더 중요한 질문입니다. AI를 잘 쓰는 것과 AI를 믿는 것은 다릅니다. 도구를 믿기보다 도구를 이해하고 활용하는 개발자가 되기 위해 노력합시다.

